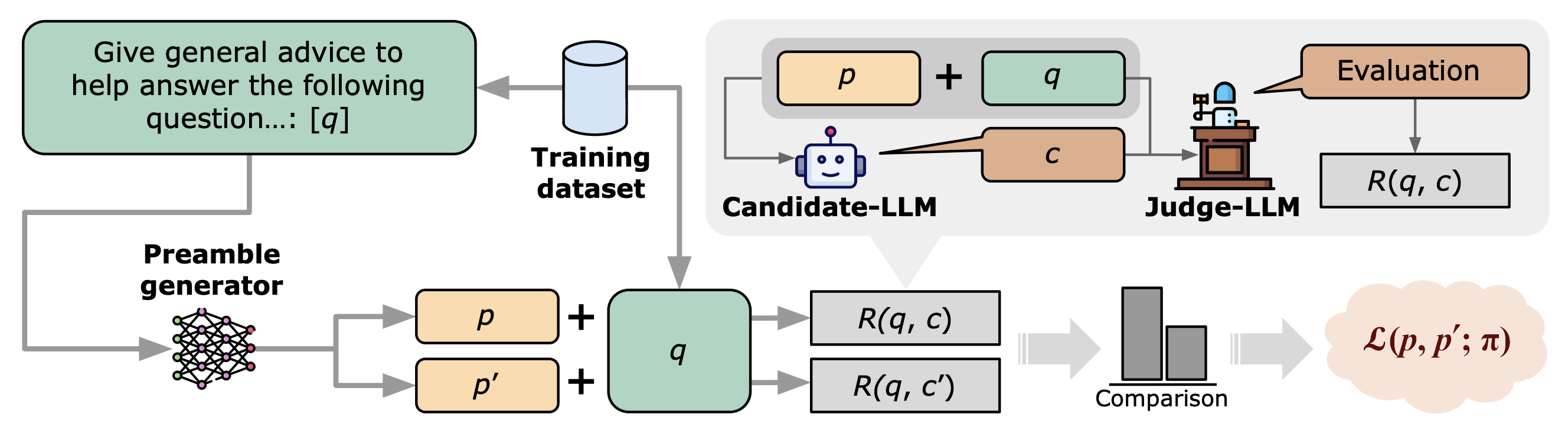
Evaluating LLMs using other LLMs to predict human preferences (LLM-as-a-judge) is a highly scalable and cost-effective framework. However, this method is vulnerable to malicious exploitation, as LLM responses can be tuned to overfit the judge’s preferences.
We propose a novel approach that uses the signal from judge-LLMs as a reward to adversarially tune models. These models generate text preambles designed to enhance downstream performance. Our findings suggest that frozen LLMs, when pipelined with these models, achieve higher LLM-evaluation scores than existing frameworks.
A key aspect of our method is its virtual undetectability, unlike other frameworks that directly intervene in the model’s response. We also demonstrate that the effectiveness of the tuned preamble generator is transferable, even when the candidate-LLM and the judge-LLM are replaced with models not used during training. These insights raise significant questions about the design of more reliable LLM-as-a-judge evaluation settings.
Twitter
Facebook
Reddit
LinkedIn
Google+
StumbleUpon
Pinterest
Email